


AI
Can Large Language Models supercharge time series analysis in Digital Marketing and eCommerce?
Sep 27, 2023
15 min read

Abstract
This article explores the potential of Generative AI (GenAI) and Large Language Models (LLMs) in enhancing Time Series Analysis (TSA) and Anomaly Detection (AD), particularly in the domains of Digital Marketing and eCommerce. It delves into the challenges these fields face, such as data multi-dimensionality, dispersion, granularity, quality, and latency. It discusses the fundamentals of TSA and LLMs, and introduces LangChain, a framework designed to facilitate the integration of LLMs and AI agents into data-aware applications in production environments. It suggests that LLMs could play a significant role in anomaly identification, contextualization, and root cause analysis; thus, it can transform AD from a mere trend line on a graph to a compelling story of an anomaly that can drive action.
Introduction: the ever-growing ocean of data
In today's hyper-connected society, data isn't just numbers or text on a screen; it's the lifeblood flowing through the veins of global industries, social interactions, and even our personal lives. According to Statista calculations, approximately 328.77 million terabytes of data are created each day, with the continuously upward trend being recently fueled by the increased demand due to the COVID-19 pandemic.
Data informs, empowers, and sometimes, perplexes us. But its true power is unleashed when we understand it, segment it, and most importantly, act on it. Yet, the deluge of data we're surrounded by often makes it akin to finding a needle in a haystack. In domains like Digital Marketing and eCommerce, this needle could be worth its weight in gold. Every click could either be a missed opportunity or a potential conversion. Every page view can unfold into a cascade of profitable user interactions. But can one sift through this ever-growing ocean of time series data to find what truly matters? How do you spot that one glitch in user behavior that could either be a potential jackpot or a red flag for fraud?
The answer could lie in Time Series Analysis (TSA) and Anomaly Detection (AD). But traditional methods are oftentimes like fishing nets with holes, missing out on subtleties or even catching the wrong fish. What’s required extends beyond just sifting through data and flagging anomalies; it involves understanding its every nuance and being able to act fast, a task that often surpasses human capability due to the size and complexity of these data problems. Artificial Intelligence (AI) and the astonishing advancements in this field, such as Large Language Models (LLMs), can become a great enabler in that respect.
AI has already revolutionized several industries, including healthcare, finance, and manufacturing, pushing the boundaries of science and technology, and changing our perception of the world. In this article, we explore the capabilities of this technology, and LLMs in particular, in making a transformative impact on TSA and AD in marketing datasets. Our focus lies not only in identifying outliers but also in understanding them and performing Root Cause Analysis (RCA), e.g., providing actionable insights to assist Chief Marketing Officers (CMOs) in achieving higher Return-on-Investment, and eCommerce Platform Managers aiming for seamless operations.

Time as a dimension: unfolding the complexities
The fundamentals of time series analysis: approaches and models
Understanding trends, fluctuations, and patterns in data sets is crucial. Time is more than just a ticking clock - it’s a dimension. A dimension that adds context, history, and above all, meaning to the data. TSA deciphers this dimension, translating sequences into actionable insights that can be used for forecasts, risk assessments, and decision-making.
TSA is a statistical technique used to analyze and model data that is collected over time. Unsurprisingly, there is a vast amount of available time series data around us. This refers to a sequence of data points taken at successive equally spaced points in time, e.g., the heights of ocean tides per day, temperature measurements per hour, annual GDP per capita, and volume of online transactions per minute. It’s important to note though, that time is not the only dimension; annual GDP per capita, for instance, can be further broken down by country or continent, which forms an additional dimension in TSA; more on this later on.
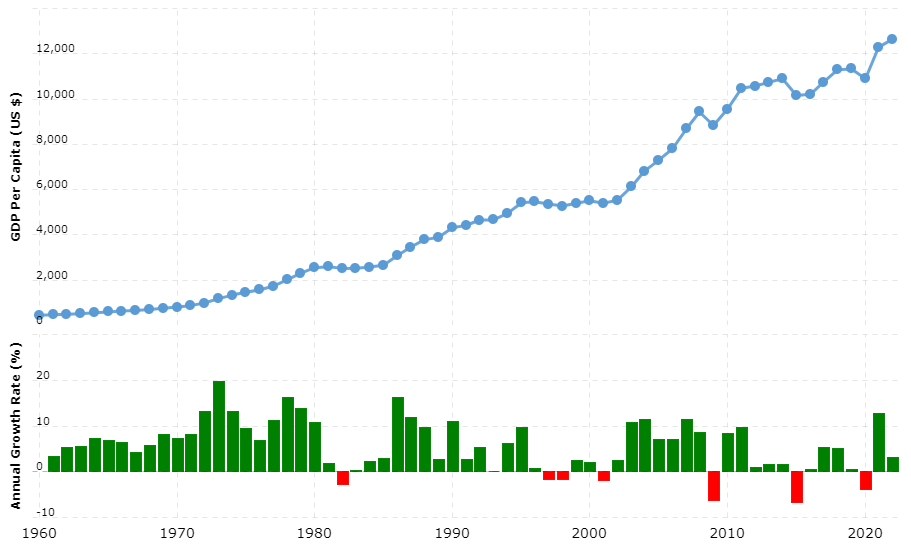
Source: https://www.macrotrends.net/countries/WLD/world/gdp-per-capita
One of the most vital, yet challenging, tasks in TSA is spotting outliers and anomalies. Whether it's identifying credit card fraud in real-time or flagging sudden changes in climate data, the potential cost of missing an anomaly and the benefits of acting on it can be enormous. There are various AD techniques that all share the same underlying goal: to identify rare events and/or unusual patterns that are significantly different from the typically expected (“normal”) ones.
Purely statistical approaches rely on measuring data deviations from known distributions. (e.g., Z-score, Dixon’s Q Test). Machine and Deep Learning approaches involve supervised, unsupervised, and reinforcement techniques, depending on whether labeled training data exist, and the use case (e.g., Support Vector Machines, Isolation Forest, and Variational Autoencoders). Then, there are expert system approaches, involving decision trees and rule-based systems, and information theory approaches, which assume that anomalies can be spotted by comparing the amount of information between data points (e.g., entropy-based). And, of course, one can combine the aforementioned approaches and algorithms, creating hybrid models (see also Hilal et al., 2022 for an excellent summarization/literature review on anomaly detection techniques).
Choosing the appropriate approach depends on the use case, data availability, size, reliability, desired accuracy and performance, as well as the need for interoperability and explainability. In general, there is a trade-off between complexity and accuracy/explainability; each approach carries its own strengths and weaknesses that one should consider when making an informed implementation decision.
The challenges in the Digital Marketing and eCommerce domains
Data granularity, quality, latency, and the multi-dimensional intricacies of user and consumer behaviors pose significant showstoppers in analyzing marketing datasets; typically, these are big, diverse, and dispersed across various tools and platforms, requiring computationally intensive ETL and analyses. The quality of the data points can be low, e.g., due to tracking issues and human errors, creating the need for extensive and consistent cleansing. For professionals who are accustomed to real-time decision-making, latency is not an option; a visitor might leave the website and never return, enormous ad budgets are spent online in a few minutes, and - quite often- there is only one shot at glory.
More importantly, the focus is broad due to the nature of the specific domains: consumer behavior and market trends are multi-dimensional. There can be thousands of different users’ micro-segments (permutations of dimension combinations) that require equally different approaches in TSA. Identifying an anomaly in one of these segments is not enough, as this might be related to an anomaly in another segment, dimension, or even on a different metric. And, of course, there can be a myriad of reasons explaining user behavior; some may be “endogenous” (e.g., online orders dropping below the expected value due to a broken call-to-action on a website), while others are “exogenous” (e.g., a popular artist mentioning a specific product in her Twitter account, thus driving product views way above the upper expected value).
The size and diversity of the data make RCA quite complex, as single-dimension and metric detection are not enough (see Thudumu et al. 2020). At the same time, the need for explainability and interpretability is enormously high. Marketers and eCommerce Managers need to understand what happened, why it happened, and what needs to be done on the spot. And they have neither the time to devote to False Positives nor the bandwidth to deal with False Negatives (e.g., missed opportunities).
In this context, TSA is not just a trend line on a graph; it weaves a narrative. It narrates customer journeys, considers market shifts, and even quantifies the impact of a single tweet on sales revenue, driving actionable insights. Quite challenging, right? Given these complexities, we must explore how recent advancements in the AI field can expand the scope and applicability of TSA and AD techniques.
GenAI in the LLM era
The Generation Leap: From AI to GenAI
AI is not a new term; it can be first traced back to the 1950s and it refers to a computer technology - but also a philosophy - driven by the idea of developing a synthetic intelligence that would match or even surpass the human brain’s capabilities. Traditionally, AI has focused on performing specific tasks intelligently, such as playing chess, self-driving cars, forecasting the weather, classifying objects into categories, recommending products, and more. These applications are often categorized as “narrow AI”.
Generative AI (GenAI) is a subfield of AI that stands out as a pioneering technology. The striking difference here refers to the generation of new content as the primary output of the models. This content includes text, images, or other media, using generative models that learn the patterns and structure of their training (input) data, and produce an output with similar characteristics.
GPT is possibly the most famous GenAI model. It was first released in 2018 by OpenAI, but no one predicted what would happen four years later; the introduction of ChatGPT (powered by GPT-3) in late 2022 left us in awe, signaling the time of a paradigm shift in our concept and perception of the world. Early experimentation and testing with the next version (GPT-4) showed that it could solve novel and difficult tasks in mathematics, coding, vision, medicine, law, psychology, and more, even without special prompting (see Bubeck et al., 2022).
ChatGPT allows individuals to interact with a GenAI technology directly, in natural language, i.e., not with code, and receive comprehensive and practical responses. This chatbot is almost freely available, it is easy and fun to interact with, and provides responses in a wide range of domains and disciplines. This can explain the number of users skyrocketing to a staggering 1 million in just five days (currently, ChatGPT has over 100 million users)! Credits for this meteoric rise should be also attributed to the Large Models (LLMs) - the unsung heroes powering this revolutionary tool!
Understanding LLMs and the LangChain framework
LLMs are a type of machine learning model within the broader category of natural language processing (NLP) and deep learning algorithms. They are designed to understand, interpret, and generate human-like text based on the data they have been trained on. They are called "large" because they consist of an extensive number of parameters - often in the hundreds of millions or even billions - enabling them to learn patterns and entity relationships from vast textual training data.
LLMs are designed to predict the next word based on the previous words. And they do this recursively to continue predicting each word to form complete sentences and paragraphs. As such, a language model at its core is trained to generate plausible output but not necessarily always correct output. This is a common point of confusion for people accusing ChatGPT of producing inaccurate responses and hallucinations.
These models’ adaptability and wide-ranging capabilities have led to a plethora of applications across multiple domains including but not limited to healthcare, legal, marketing, and financial services. The advantage of using LLMs is their ability to understand context and generate coherent and contextually relevant text, which can be incredibly valuable for various applications where nuanced language and understanding are critical.
But - you guessed right? - while LLMs are definitely the game-changers in the realm of GenAI, there are several limitations when it comes to deploying and using a technology like this in a production environment:
- There are memory limits in various LLMs, which can result in context loss when the user inputs (prompts) exceed them; and this may result in lower-quality responses, particularly in cases where long (e.g., few-shot and chain-of-thought) prompting is needed to provide context to an LLM by infusing domain-specific knowledge.
- There exist lock-in inefficiencies when integrating a production application with a particular LLM API; this means that switching between different LLM models (and APIs) within the same application is troublesome resulting in integration challenges.
- The structure and format of both the input and the output are pre-specified and should comply with the specific LLMs’ requirements; ideally, instead of a text response, it would be better to have a structured response that could be used programmatically - imagine the scenario where the output by an LLM becomes the input for another LLM or application!
- Real-time connection to the “outside world” is limited. Typically, LLMs are pre-trained on a remarkable size of data but with a clear cut-off date (e.g., September 2021 for GPT-4). This means that any resource created after this date won't be included in the responses and the model won’t be able to access new information, such as crawling a website.
Integrating LLM models in production-ready applications can be a time-consuming and challenging task due to their unique architectures, API schemas, and compatibility requirements. What seems to be missing is a level of abstraction, i.e., a layer or framework that can sit between the LLMs and the applications. Well, this is not missing anymore, thanks to the introduction of the LangChain framework.
LangChain simplifies the creation and integration of data-aware and agentic applications using LLMs, by standardizing I/O, enabling the connection to various data sources and LLMs, and empowering dynamic model interaction. This framework creates chains of interconnected components from multiple modules: prompt templates, standardized access to various LLMs models and APIs, agents with access to an arsenal of tools for deciding on an action, off-the-shelf chains for binding together different LLMs and workflows, memory setting controllers, and callbacks for logging/indexing the intermediate steps of any chain.
This framework could very well be the springboard that catapults NLP and GenAI applications to new heights across industries by fully addressing the limitations of LLMs mentioned above. But could it also contribute to addressing the challenges of TSA and AD mentioned before, particularly in the Digital Marketing and eCommerce domains?
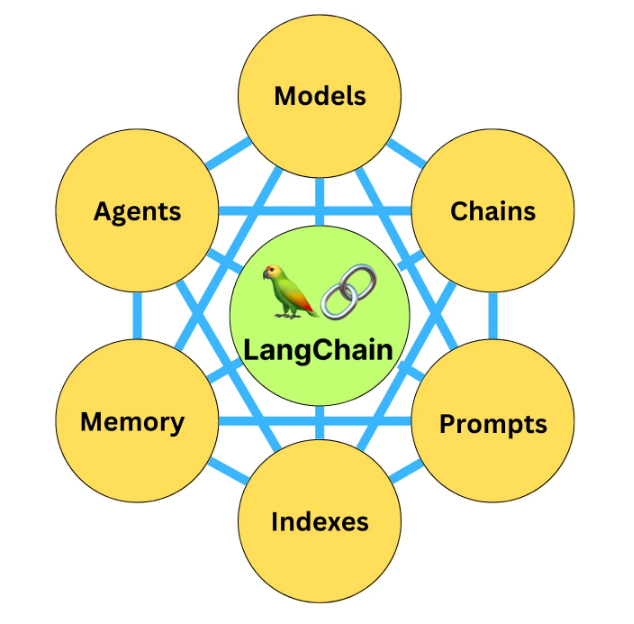
Source: https://blog.bytebytego.com/p/how-to-build-a-smart-chatbot-in-10
Βridging two worlds: Reimagining Time Series Analysis with GenAI
In this section, we aim to define the applicability of LLMs in these dynamic domains, examining their role in anomaly identification, contextualization, and root cause analysis. The ensuing discussion provides an aspirational overview of how LLMs are poised to revolutionize conventional TSA methods.
The first potential application of GenAI within TSA pertains to the visual scrutiny of voluminous time-series graphs for anomaly flagging. Though traditionally falling under the purview of 'narrow AI' and utilized in supervised paradigms, such as quality control in manufacturing, GenAI can substantially augment this process. Specifically, GenAI models can generate graphs that incorporate expected data points, which can serve as invaluable visual aids in crafting a comprehensive narrative around anomalies.
Then, GenAI models stand in stark contrast to conventional static TSA algorithms by virtue of their inherent ability to adapt and learn dynamically. This feature is critically beneficial in fast-evolving domains such as Digital Marketing and eCommerce, where consumer behavior is in perpetual flux and manual calibration is unwieldy. GenAI's ability to continuously learn from new data and user feedback provides a robust, self-adjusting solution.
Moreover, the profound capabilities of LLMs can be also harnessed to systematically examine and categorize historical incidents. Envision an eCommerce manager collaborating with her team through a multitude of channels, such as email, Slack, or Jira. LLMs can meticulously analyze past incidents, communications, and actions to establish a refined taxonomy of anomalies and corresponding actions. This kind of domain-specific, actionable knowledge significantly enhances the efficacy of subsequent LLM prompting.
Another promising contribution of GenAI to TSA could be in the realm of RCA. While traditional TSA tools excel at identifying anomalies, they seldom offer insights into the underlying root causes. GenAI can address this gap by generating comprehensive, multi-dimensional analyses. For instance, upon detecting a sudden spike in web traffic, GenAI can cross-reference a plethora of variables—ranging from seasonal trends and company metrics to market dynamics and social media activity—to construct a compelling narrative explaining the probable cause and recommending an action. The multi-agent, interdependent nature of LangChain architecture lends itself perfectly to this form of layered analysis where the output of one model becomes the input for another. In other words, TSA could benefit from LLMs’ ability to make well-informed decisions by analyzing information from both textual and numerical (time series) data and extracting insights, leveraging cross-sequence information (Yinfang et. al., 2023).
Regarding the high interpretability needs of AD models in the specific domains, a pivotal advantage of LLMs is their ability to produce summarized outputs in natural language, thereby eradicating the need for technical jargon. Moreover, the variability and determinism in LLM outputs can be fine-tuned through parameters like 'temperature' and 'top-n,' thereby customizing the generated narratives to suit various stakeholders, from data scientists to marketing professionals. This level of transparency also addresses the often-cited 'black-box' critique of AI, thereby enhancing trust and interpretability. This is particularly true in cases of emerging prompting frameworks, such as the Chain-of-Thought (CoT - see Wei et al., 2022), the Algorithm-of-Thought (AoT - see Sel et al., 2023), the Tree-of-Thought (ToT - see Long, 2023) and Least-to-Most (L2M - see Zhou et al., 2023). In these frameworks, intermediate reasoning steps can be logged and inspected.
The schematic diagram below depicts a GenAI-powered Advanced Anomaly Detection system elucidating the functionalities and the interoperability inherent in a LangChain architecture. It’s worth highlighting that systems that already integrate advanced AD components—capable of performing multi-dimensional analysis, anomaly grouping, contribution analysis, prioritization, and producing textual description—will hold a significant competitive edge since their output is the trigger for the LLM-powered system.
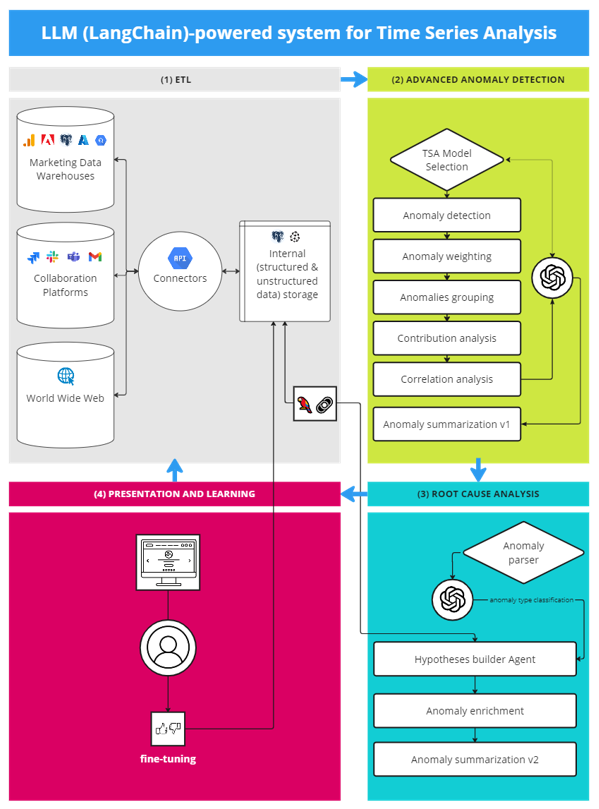
Note: The ‘Hypotheses builder Agent’ involves a sub-system of novel prompting frameworks (e.g., CoT, AoT, and ReAct) that can enhance the Agent in formulating and testing hypotheses iteratively., This process involves using structured and unstructured data from both the action space and the environment.
Some concluding remarks
The synergy between TSA and GenAI technologies, such as LLMs, presents an exciting frontier. In TSA, the multi-dimensionality that often serves as a hurdle can transform into a compelling asset when integrated with GenAI. Advanced models can swiftly adapt to market trends and decipher seasonality, but, more importantly, factor in seemingly unrelated events - such as celebrity tweets or new product launches - to craft a comprehensive narrative surrounding data anomalies. Crucially, this narrative extends beyond mere diagnostics to offer proactive approaches for AD.
In the specialized realms of Digital Marketing and eCommerce, GenAI elevates analytical capabilities to levels unattainable by manual scrutiny or traditional statistical methods. Marketers can obtain more than a snapshot; they could receive a comprehensive overview of their campaigns' performance. Likewise, eCommerce managers would no longer need to speculate about the reasons for a dip in conversions. AI-powered systems and data analysis agents will be able to deliver immediate, actionable insights.
The incorporation of GenAI into TSA represents not a mere incremental advance but a quantum leap. It promises automated data processing, real-time analytics, and the development of predictive and explanatory models that genuinely "understand" data in a manner akin to human expertise.
However, it's also crucial to temper this enthusiasm with a nod to the ethical complexities surrounding AI integration. Concerns about data privacy and social responsibility are valid, yet not insurmountable obstacles. By employing responsible AI practices and emphasizing explainability, we can navigate these ethical challenges responsibly.
References
- Bubeck, S., Chandrasekaran,V., Eldan, R., Gehrke, J. Horvitz, E., Kamar, E., Lee, P., Lee, Y.T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M.T., & Zhang, Y. (2023). Sparks of Artificial General Intelligence: Early experiments with GPT-4, Cornell University, Computer Science > Computation and Language, arXiv: https://arxiv.org/abs/2303.12712
- Hu, A. (2023, June 6). How to Build a Smart Chatbot in 10 mins with LangChain, ByteByteGo. https://blog.bytebytego.com/p/how-to-build-a-smart-chatbot-in-10
- LangChain Docs (2023). https://python.langchain.com/docs/get_started/introduction.html
- Long, J. (2023). Large Language Model Guided Tree-of-Thought, Cornell University, Computer Science>Artificial Intelligence,, arXiv: https://doi.org/10.48550/arXiv.2305.08291
- Sel, B., Tawaha, A.A., Khattar, V., Wang, L., Jia, R., & Jin, M. (2023). Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models, Cornell University, Computer Science>Computation and Language, arXiv: https://doi.org/10.48550/arXiv.2308.10379
- Talaviya, A. (2023, July 27). Building Generative AI Applications with LangChain and OpenAI API. Analytics Vidhya. https://www.analyticsvidhya.com/blog/2023/07/generative-ai-applications-using-langchain-and-openai-api/
- Taylor, P. (2023, August 22), Amount of data created, consumed, and stored 2010-2020, with forecasts to 2025, Statista, https://www.statista.com/statistics/871513/worldwide-data-created/#statisticContainer
- Thudumu, S., Branch, P., Jin, J., & Singh, J. (2020). “ A comprehensive survey of anomaly detection techniques for high dimensional big data.” Journal of Big Data 7 (42), https://doi.org/10.1186/s40537-020-00320-x
- Waleed, H., Gadsden, A.S., & Yawney, J. (2022), Financial Fraud: A Review of Anomaly Detection Techniques and Recent Advances, Expert Systems with Applications, 193, 116429, ISSN 0957-4174, https://doi.org/10.1016/j.eswa.2021.116429
- Wei., J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E.H, Le, Q.V., & Zhou, D. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Part of Advances in Neural Information Processing Systems 35 (NeurIPS 2022) Main Conference Track, https://doi.org/10.48550/arXiv.2305.15778
- Yinfang, C., Huaibing, X., Minghua, M., Kang, Y., Xin., G., Liu, S., Yunjie, C., Xuedong, G., Hao , F. Ming, W., Jun, Z., Supriyo, G. Xuchao, Z., Chaoyun, Z. Qingwei, L., Saravan, R., & Dongmei Z. (2023). Empowering Practical Root Cause Analysis by Large Language Models for Cloud Incidents, Cornell University, Software Engineering, arXiv: https://doi.org/10.48550/arXiv.2305.15778
- Zhou, D., Scharli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., Le, Q., & Chi, E. (2023). Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, Cornell University, Computer Science>Artificial Intelligence, arXiv: https://doi.org/10.48550/arXiv.2205.10625




Start your 30-day free trial
Never miss a metric that matters.


No credit card required
Cancel anytime
© 2023 Baresquare | All rights reserved.


